Chapter 5 VC theory
In Chapter 4 we defined the shatter coefficient as the number of times we can intersect \(\{X_1,...,X_n\}\in\mathcal{X}\) with subsets \(A\) of \(\mathcal{X}\) that belong to the family \(\mathcal{A}\), in particular:
\[ \begin{equation} \begin{aligned} && S(X_1^n,\mathcal{A})&= \left|\{A\cup\{X_1,...,X_n\}:A\in\mathcal{A}\} \right| \\ \end{aligned} \tag{5.1} \end{equation} \]
We further defined:
\[ \begin{equation} \begin{aligned} && S_{\mathcal{A}}(n)&=\max_{X_1,...,X_n}S(X_1^n,\mathcal{A}) \\ \end{aligned} \tag{5.2} \end{equation} \]
Clearly, we have that \(S(X_1^n,\mathcal{A})\le2^n\), where \(2^n\) is simply the total number of subsets of \(n\) points: each point can either be in a given subset or not.
Suppose the class \(\mathcal{A}\) shatter the \(n\) points. This means that for each possible subset, we can find a set in \(\mathcal{A}\) that can be intersected with the subset. In the context of our initial problem \(\mathbb{E} \max_{A\in\mathcal{A}} |P_n(A)-P(A)|\) and the VC theorem, this means we are in trouble: we expect that overfitting will occur.
5.1 VC dimension
Relating this back to empirical risk minimization and classification, the VC dimension corresponds to the complexity of our family \(\mathcal{C}\) of classifiers. The higher the VC dimension, the higher the shatter coefficient associated with \(\mathcal{C}\) for given \(n\): ultimately, high VC dimensionality can be thought of as an increased risk of overfitting.
5.1.1 Feature maps
We often want to find an upper bound for the VC dimension of a family of classifiers. To do so in practice we just need to determine the number of feature maps \(r\).
5.1.2 Examples
Firstly, observe that for the set of linear half-spaces \(\mathcal{A}=\left\{ \{ X: \sum_{i=1}^{d} w_i \phi_i(X)=\mathbf{w}^T\phi(X)\ge0\}:\mathbf{w}\in \mathbb{R}^d\right\}\) we in fact have \(V_{\mathcal{A}}=d\): we can simply take each element of \(X\) as a feature, so \(\phi_1(X)=X_1, ..., \phi_d(X)=X_d\).
5.2 Stuctural risk minimization
Let \(\mathcal{C}^{(1)}\subset\mathcal{C}^{(2)}\subset...\) be a sequence of classifiers. Then for their corresponding VC dimensions we have \(V_1\le V_2\le...\). Let \(\bar{g}_k\) denote the best classifier among the whole sequence - that is the classifier that minimizes true risk - and let \(g_n^{(k)}\) denote the classifier that minimizes empirical risk (potentially all the way to zero). We know that the empirical risk minimizer is prone to overfitting, but we also saw in Chapter 4 that we can bound the risk of overfitting. In particular, using the result in ?? we have that the overfitting error can be bound by
\[ \begin{aligned} && R(g_n^{(k)})-R_n(g_n^{(k)})&\le c \sqrt{ \frac{V_k \log n}{n}} \\ \end{aligned} \] where \(c\) is some constant. We explicitly refrain from using absolute values here to demonstrate that we expect the difference expressed in this way to be positive. With this in mind, it seems reasonable to use this knowledge to inform our choice of \(k\), that is the complexity of our classifier. In structural risk minimization we incorporate the bound as a penalty on top of the empirical risk. This is referred as complexity regulation.
Complexity regularization involves choosing the value of \(k\) for which \(R_n(g_n^{(k)})+c \sqrt{ \frac{V_k \log n}{n}}\) is minimized. Let \(g_n\) denote the classifier obtained through penalized empirical risk minimization. Then one can prove that
\[ \begin{aligned} && \mathbb{E} R(g_n) - R^*&\le \min_k \left( c \sqrt{ \frac{V_k \log n}{n}} + R(\bar{g}_k) - R^* \right)\\ \end{aligned} \]
where \(R^*\) is the Bayes risk, \(c \sqrt{ \frac{V_k \log n}{n}}\) is an upper bound for the excess risk in \(\mathcal{C}^{(k)}\) - that is \(R(g_n^{(k)})-R(\bar{g}_k)\) - and \(R(\bar{g}_k) - R^*\) is the approximation error (bias) of the family of classifiers that we restrict ourselves to. Figure 5.1 illustrate this approach.
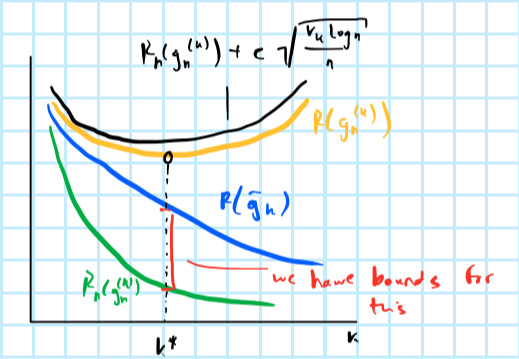
Figure 5.1: (PLACEHOLDER) Structural risk minimization.
Note that \(c \sqrt{ \frac{V_k \log n}{n}}\) is not the best bound and in fact we have already seen improved versions of this, in particular the Rademacher Average in Chapter 4. We will cover complexity regularization in more detail in Chapter 8.